
Did you find a good machine learning (short: ML) model for your data science project that satisfies the requirements? Would you like to put the model into production, but do you wonder how?
No worries, you are not alone. Based on Gartner research, almost half of the machine learning models won’t make it into production due to challenges with the deployment process. In addition, the report provided by VentureBeat states that even 90% of data science projects will not make it into production because of a lack of collaboration between data scientists, ML engineers, and DevOps specialists.
In this article we would like to shed light on the tools and practices of ML engineering. We believe that ML engineering skills are critical to put data science projects into production.
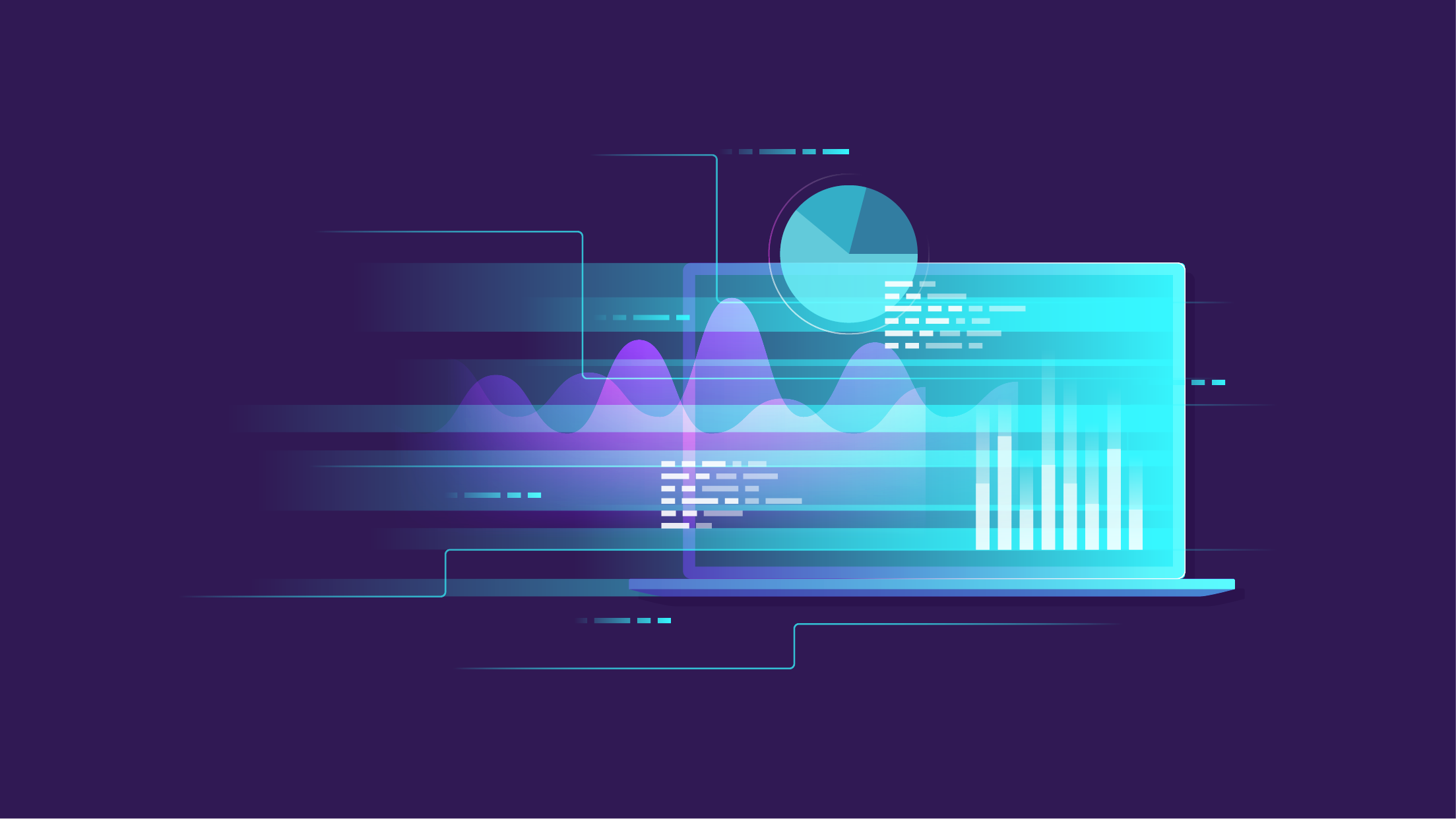
In the process of finding such a suitable ML model we iterate in a so-called data science cycle. It is important to remark that the lifecycle as discussed here represents only the technical aspects of a data science project. Usually, data science projects also include an initial project phase that could be, for instance, represented by a kick-off workshop. In such a workshop the business use-case and the corresponding data science solution will be designed.
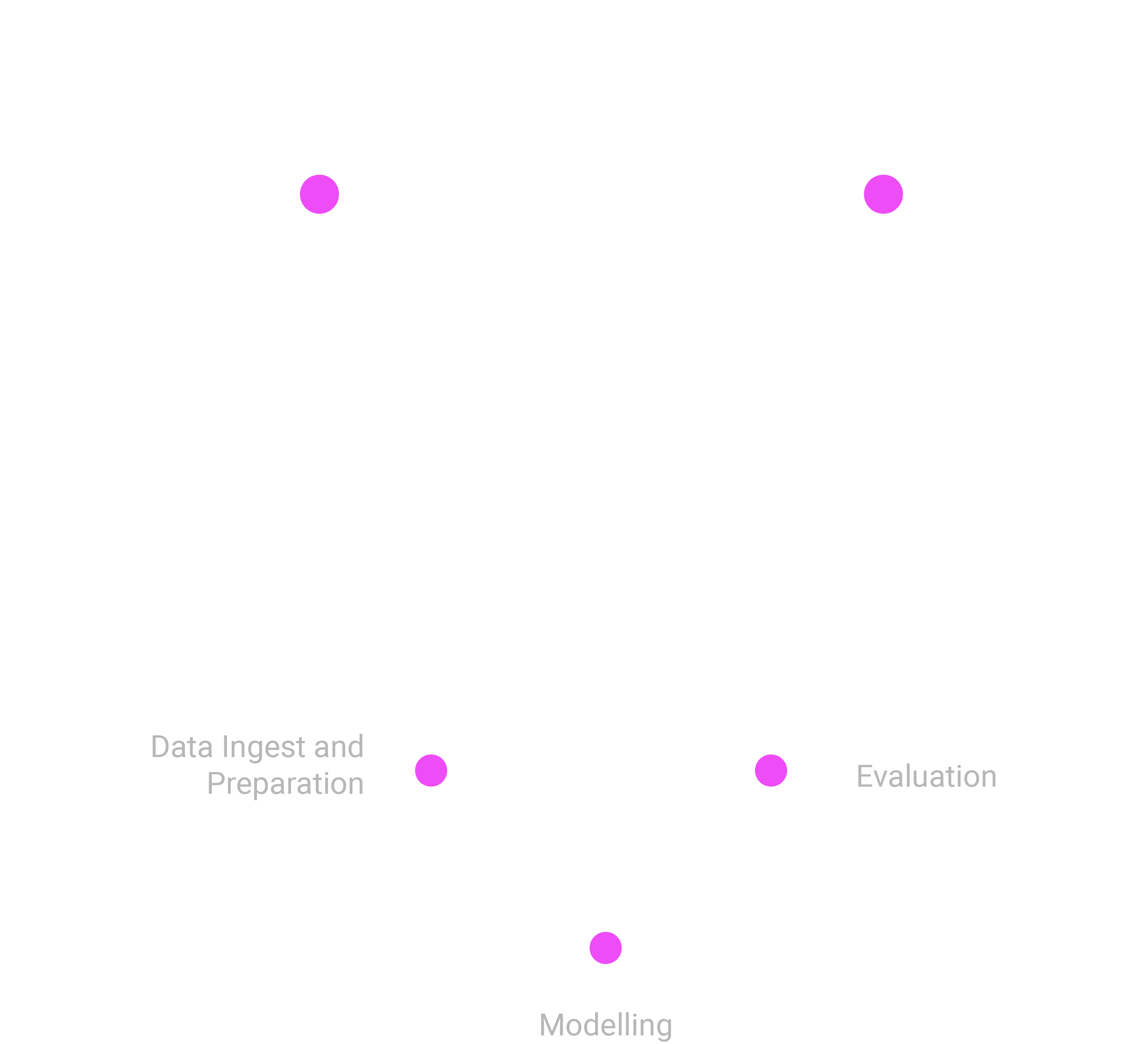
Usually, the cycle starts with data ingestion and preparation. Here you collect relevant data from various data sources, like databases, file systems, or any data platforms.
Next you prepare and organize your data in a manner that is comfortable for you to work with as a data scientist. In the next iteration step you analyze the data and develop a model for your use-case. To analyze the data, you can use visualization techniques, clustering algorithms, correlation metrics and much more.
During evaluation you design necessary metrics to measure the progress and define necessary requirements for the model to be accepted.
The above-described steps are just one possible scenario in a data science project. In practice, the steps depend on the use-case and the nature of the data.
These iteration steps help you to find an appropriate model. However, the above cycle does not help you to provide your model as a service to the users. In fact, the cycle is a part of a larger cycle which we will call Machine Learning lifecycle (short: ML lifecycle):
The ML lifecycle provides a framework to deploy data science projects, but it also helps you to think one step ahead. Specifically, after the operationalization and monitoring process, there comes a next step: Feedback. This step gives you an idea of how to evaluate the monitoring by communicating with the end-user which is critical for improving your ML model or service.
Now, you have an idea of what to expect if you want to work on data science projects. In the following sections, we would like to explain machine learning engineering activities along the ML lifecycle.
First, we will focus on the data science step. In this step one of the most challenging parts is to take care of reproducibility of results and traceability. Therefore, we will introduce two ML engineering practices that will help you to manage your data science projects.
The second section is devoted to the operations step, where we describe activities that are necessary to create ML services from your machine learning models. Moreover, we also show a standard solution architecture that enables you to monitor your machine learning models. This section is crucial for deploying data science projects effectively.
In the third section, we will focus on the feedback step, specifically there are two aspects that need to be considered when executing this step. Finally, in conclusion we will summarize the contribution and work of a machine learning engineer.
In the data science cycle, as described above you mostly perform data ingestion, preparation, modeling, and finally evaluation. Thanks to the evaluation you can decide if the developed model satisfies the acceptance criteria. In most cases, you repeat these steps and if the data science applications do not consist of a version control system of data, models, and performance results, then the ML project becomes hardly trackable, and results becomes irreproducible. For these reasons, it can be helpful to apply some ML engineering practices.
Suppose you are working on a regression project, and your data set is table-based, and you are at the end of the evaluation step of the first data science cycle. In the evaluation you used for example Excel to compare different results and a few Jupyter notebooks to visualize the training history. After a discussion with stakeholders, you decided to extend the data set with new samples and new features. To maintain reproducibility, you must keep both data sets and rerun your process, i.e. execute train scripts and the Jupyter notebooks. Hence, you must differentiate between multiple different Excel files and save the results that are stored in your Jupyter notebooks. As a result, you have extra work for saving results generated from Jupyter notebooks. Lastly imagine doing this every time you evaluate your new model. This procedure does not scale. Especially, if you must answer after several evaluations:
Answering the above questions can result in reproducing completely different evaluation results.
ML engineering offers practices to avoid this tedious work. We introduce two possible practices.
First ML engineering practice: Coupling your data to the code-version can help to reproduce your results. Additionally, it helps to prevent searching which data science code-version matches the right version of your data. Thus, it makes your results credible, and you can seamlessly execute data science code without searching for the right version.
The result of the first practice:
To implement this practice, we recommend using a dependency management tool. There are several options, some of them are open source and free to use, some must be purchased or are subscription based. For instance, the tool DVC is an open-source option.
Second ML engineering practice: Use automated experiment tracking of your data science project to make the progress of model training and results transparent. We recommend tracking the progress of model building and results in one common directory or database. The intention is to make the collaboration of multiple data scientists easier.
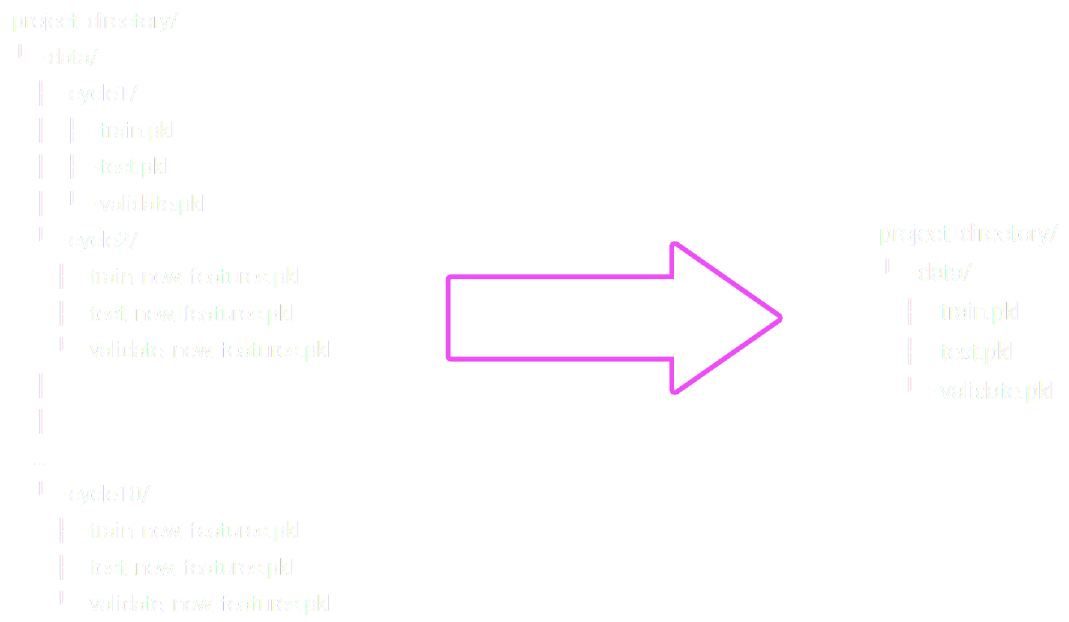
Suppose we do not use an experiment tracking for our data science cycle, the data science project has the following form:
So, running this multiple times we get:
Maintaining such a structure is time consuming and does not scale. Additionally, this becomes even more error prone if a team of multiple data scientists works on this project due to individual style of storing and sharing data. Lastly, the following task are hard to execute:
However, if the second practice is employed, none of the above difficulties will arise. The following figure represents the transition.
As for the first ML practice, we recommend using a tool. There are several options, like the open-source option called MLflow or Sacred.
Once you have developed an ML model that is capable of solving your task, the next step is to prepare it for the intended use-case. That includes the operationalization of the ML model and its monitoring. An example scenario on how the operationalization can look like is visualized below.
To begin, we take a look at containerizing the model. Here, we create a package that contains the model and everything it needs to be executed. For example, the necessary libraries and the Python environment with all the required packages installed. Often, even a minor change in the package versions can lead to different results or errors during inference. A known and well-suited technology here is Docker. Having a packaged model inside of a Docker container allows us to distribute the model to any host system that handles the inference without manipulating that system.
Now, you have a system that hosts the packaged ML model. Further down the pipeline, end users need access to the model. One way to accomplish that is to provide a backend service implementing a REST API. That service accepts requests from the end users, runs an inference on the model given input data and returns the results to the end users. There are multiple ways to implement this, a fast and elegant way is using FastAPI or for more complex projects Django.
Looking at a fully automated pipeline, one nice and handy feature is still missing: the connection to data sources. An advantage of fetching input data automatically from a given source is that the end user does not need to download and upload these data manually. Popular data storage types that are worth looking into are S3 storages – where S3 stands for Simple Storage Service – and (No)SQL databases like Amazon Dynamo, PostgreSQL, MongoDB. But also, data streams like Apache Kafka (Use Case) are possible.
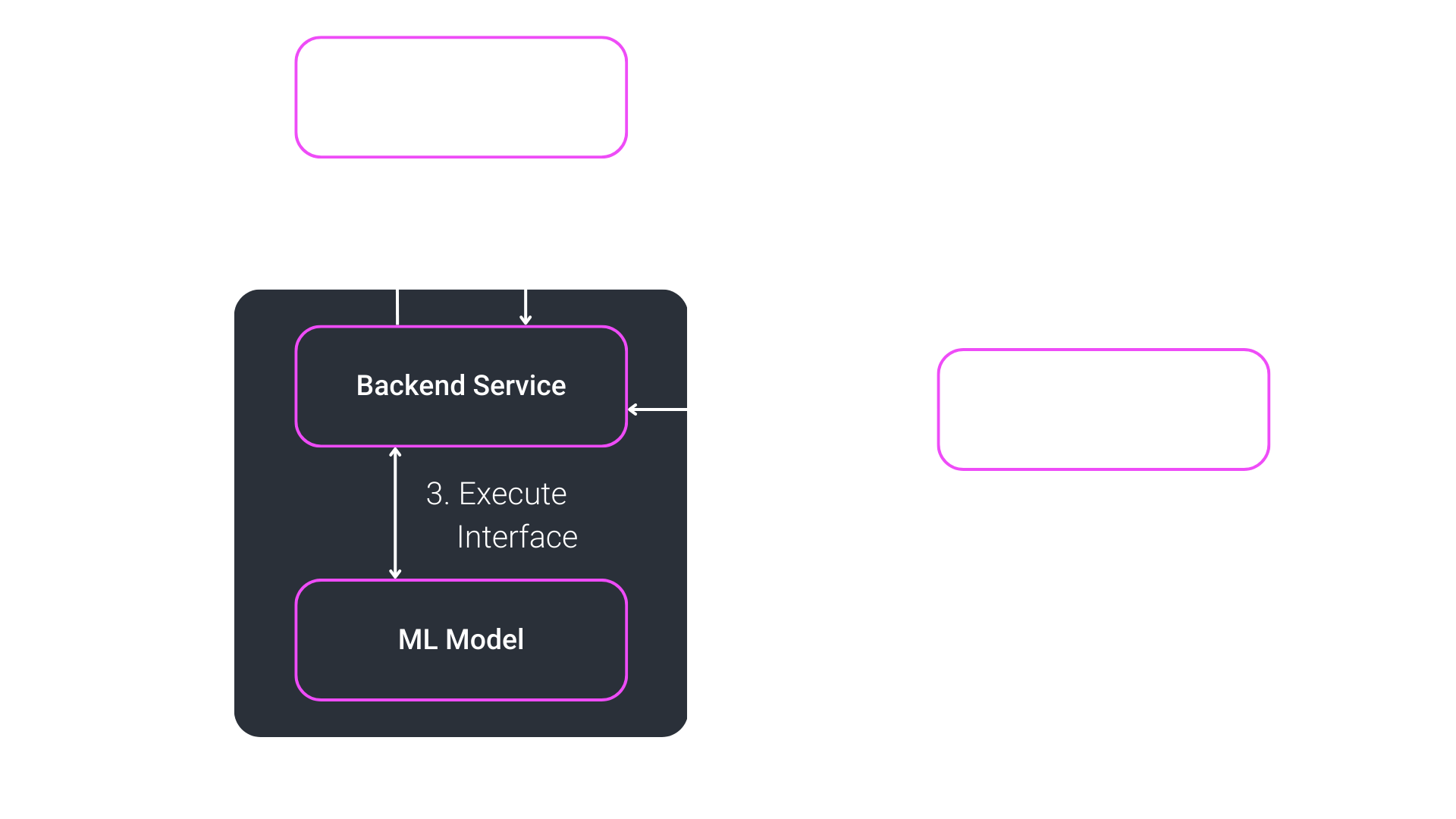
Having an operational pipeline that allows for the dynamic inference of an ML model, you might want to monitor everything from the request to the response containing the result. That consists of logs during the inference (input and output, time needed for execution) but further also the automatic gathering of false negatives, false positives and potential outliers. Collecting these data helps to improve the Machine Learning model in stability and performance. This information can be stored, e.g. on an S3 storage.
After all the data science and the integration of the final model into an easy-to-use environment, there is one little step to mention.
Your model is now able to infer real and new input data. Final end-users can trigger the inference by calling the API endpoint and after successful execution they retrieve the model output with the response of the API.
In order to complete the ML lifecycle that we mentioned at the beginning of this article, we need to introduce feedback from the end users who use the model with real world data. There are two points we would like to mention. First, evaluate the deployed model on the false negatives that were gathered during monitoring. How can the model predictions of the samples be improved to be correct? Second, evaluate the deployed model on feedback coming directly from the end users. Are there any new data or input features that might be supportive? Is the model output usable for the end user or is there room for improvement?
This feedback automatically connects the operations part in the ML lifecycle with the data science part. Thus, the lifecycle is complete.
In this article, we explored the different stages of the ML lifecycle and how they are connected. In order to repeatedly develop and deploy a productive ML model, these stages lay the necessary foundation.
Having a data science project on its own does not solve the question “How do I easily get my working model to the end users?”. The integral part that makes that possible is ML engineering. That field uses different technologies for data modeling and creating an infrastructure that connects the data scientists and the end users to work together to improve ML models. Once that environment is built, models can be developed and dynamically deployed.
Once you manage to provide an ML-service using the ML lifecycle, you will recognize the need to provide new opportunities and improvements to your ML service as fast as possible. However, executing the complete ML lifecycle manually is slow, error prone and with time the code quality decreases. For this reason, the so-called Continuous Integration/Continuous Delivery (CI/CD) is implemented along the ML lifecycle. So, stay tuned for our next blog article about CI/CD in ML projects.
