

In this blog post, we would like to give you a brief insight into the world of EdgeAI.
Unlike traditional methods, where data processing is mostly done in the cloud, EdgeAI enables data to be processed right where it is generated. The term "edge" refers to devices at the edge of a network that can process the data. This technology has some advantages, but it also presents us with challenges. We focus on one specific challenge - the limited processing power and storage capacity of edge devices. As a solution, we present pruning and quantization, which can significantly reduce model size and speed up inference without significantly compromising model accuracy.
"EdgeAI" refers to the shift of data processing with AI to the edge of the network, i.e., where the data is generated. In an era of digital transformation, the integration of AI into a wide range of devices - from industrial machines to networked production facilities - is becoming increasingly important in the context of Industry 4.0. This development is crucial, as it helps companies optimize their production processes and increase efficiency. By implementing and using EdgeAI, companies can monitor and adapt their production processes in real time and develop innovative solutions to overcome the specific challenges of modern industry. These challenges can range from improving product quality to reducing downtime. This could be through automated quality assurance or early maintenance of machines based on the data collected and analyzed.
According to a report by Fortune Business Insights[1], the global market for this emerging technology is expected to grow from around $20 billion in 2023 to around $110 billion in 2029, and has the potential to fundamentally change the way we use AI.
Direct data processing "at the edge" results in several benefits, including:
But as with any new technology, there are challenges to overcome.
The integration of powerful AI models on edge devices is challenging due to the limited processing power and storage capacity of these devices. In particular, the growing complexity of modern models such as GPT-3, with its 175 billion parameters and a memory requirement of around 350 gigabytes, illustrates this problem. As models become more complex, the number of parameters increases, making it difficult to scale to the limited resources of edge devices. It is important to note that these challenges apply not only to highly complex models such as GPT-3, but also to simpler models. Even models with a smaller number of parameters can be problematic due to the limited processing power and memory capacity of edge devices.
Networking edge devices is another challenge, especially when they have limited or unreliable Internet access. This makes it difficult to efficiently transport models or large amounts of data between the edge devices and the central infrastructure. In future blog posts, we will take a closer look at these challenges.
Despite the increased security provided by EdgeAI, it is important to remember that sensitive data is collected and processed directly on the devices. This poses potential security risks and could provide an attack surface for attackers. It is therefore critical to ensure the security and confidentiality of the data.
In this blog post, we want to take a closer look at the challenge of limited resources and answer the following questions: How can we optimize our AI models to work efficiently without being constrained by the limited memory and processing power of edge devices? How can we improve inference speed to best support applications such as real-time video analytics or automated anomaly detection in industrial devices?
The goal of this article is to answer these questions by defining a potential use case and presenting techniques to overcome these challenges of EdgeAI. We first introduce the use case, then describe the dataset and the model. We then provide insights into two model compression strategies - pruning and quantization - and compare them. Finally, we draw conclusions from our findings and look at possible developments and challenges in this area.
Non-intrusive load monitoring (NILM) is a technology that makes it possible to monitor the energy consumption of individual devices in a home or business by analyzing the total electrical load at a central distribution point.
Suppose you operate a production line that is equipped with a large number of motors. Each of these motors, whether it is the drive motor of a conveyor belt, the servo motor of a robot or the stepper motor of a positioning system, has its own specific "energy consumption fingerprint" that can be detected using NILM. For example, the drive motor may have a peak energy consumption during peak load times, while the servo motor has a variable energy consumption that depends on the complexity of the robot's movements.
When a machine or device in a production plant is started up, the NILM system identifies the specific energy consumption pattern of that machine from the overall power consumption and transmits this information to the company's monitoring system. Based on this data, detailed reports can be generated, for example, on the power consumption of individual systems. This enables decisions to be made that can reduce power consumption and cut costs.
Another use case that is directly applicable to industry is predictive maintenance with NILM. Predictive maintenance refers to the process of maintaining devices at an early stage to prevent unexpected failures. In the case of NILM, this maintenance is based on deviations in the typical power consumption pattern of the device. By implementing NILM, companies can detect anomalies in power consumption early and take preventative measures to avoid failures and maximize the efficiency of their production facilities. This approach allows companies to optimize their maintenance strategies and minimize downtime, ultimately leading to increased productivity and cost efficiency.
In this blog post, we will demonstrate the capabilities of NILM on the Edge using the Tracebase dataset.
The Tracebase dataset is a collection of power consumption traces from electrical devices that can be used for research in the field of energy analysis. The traces were collected from individual electrical devices at an average rate of one sample per second. The data was collected in several German households in Darmstadt over several days. The dataset consists of 32 different device classes with 122 different devices and a total of over 1200 power consumption traces.
We chose a 1D convolutional neural network (1D-CNN) to identify the individual devices. The layers of a 1D CNN are designed for one-dimensional data, such as time series [3]. The model has five 1D-CNN layers, each followed by a max-pooling layer to reduce overfitting. The last two layers are fully connected. We used the ReLU function as the activation function and a softmax function after the output layer. The model was implemented and trained using PyTorch.
Some metrics need to be defined to evaluate the impact of the model compression methods presented later. In the spirit of EdgeAI, we put special emphasis on the model size in megabytes, the inference speed for a batch of data, the BCE loss and the F1 score, each computed on the test set. BCE loss and F1 score are metrics that describe the performance of a model in terms of the accuracy of its predictions. The BCE loss is minimized during the training process, i.e. we aim for the lowest possible value. The F1 score is between 0 and 1, where 1 indicates the best possible classification performance.
The basic model requires 0.83 MB of memory. It takes 54.9 ms to process one input. The model has a BCE loss and F1 score of 2.97 and 0.68, respectively. The values are solid, but there is room for improvement.
In this section of the blog post, we want to address the above questions about edge computing and introduce two techniques that can be used to overcome the challenge of limited resources.
Two of the most important model compression techniques that can reduce the size and complexity of models without significantly compromising accuracy are pruning and quantization. These methods can be used alone or in combination.
In the following, we will introduce these methods and test and compare their effects on the model.
Pruning is a technique that removes unnecessary or unimportant weights from a model by comparing the weights to a threshold or by evaluating the impact of the weights on model performance. Pruning can significantly reduce the number of parameters and necessary computations in a model, which can lead to faster inference and smaller model size.
Pruning can be divided into two main types. Structured pruning typically involves removing entire neurons, filters, or layers, which can result in a highly compressed network and faster inference without sacrificing accuracy. In addition, this type of pruning means that when a neuron is removed, all associated weights are also removed. Unstructured pruning refers to the removal of individual weights, which can result in an irregular pattern of zeros in the network.

Given our use case in EdgeAI, where real-time analysis of data is critical, we place a high value on inference speed. This is why we chose structural pruning. In practice, this technique has a wider range of applications than unstructured pruning because it does not require any special hardware, such as AI accelerators.
We have already emphasized the role of weights, but how do we determine the relevance of individual parameters or even filters? In the following, we will address this question and explain some common pruning criteria.
An intuitive way to determine the importance of a weight is the magnitude-based approach. This approach uses mathematical methods to estimate the influence of a weight on the overall result of the network. The advantages of magnitude-based pruning are simplicity of implementation and low computational cost, since the importance of each weight can be determined by its magnitude alone. Absolute value is not the only order of magnitude that can be used. Another example of an order of magnitude is the L2 norm.
The importance of a weight can also be determined by the effect that pruning that weight has on training loss. This criterion has the potential to yield small weights that are important for model accuracy. However, this method is computationally expensive and introduces a new form of complexity into the pruning process.
There is also the possibility of randomly removing weights from the network. This approach is considered a simple and general baseline that works well and can be used as a benchmark for more complex pruning methods.
It remains to be considered whether we apply the chosen criterion to the whole model, i.e. globally, or per layer, i.e. locally. This is called global and local pruning.
Global pruning usually produces better results than local pruning. However, local pruning is easier to implement, so we recommend starting with it. We have tested both methods and present our results in the next section.
For the implementation of structured pruning and our benchmarking, we used Torch Pruning (TP).
TP is an open source toolkit that allows to perform structured pruning for different neural networks, such as CNNs or large language models. It is based on the DepGraph algorithm. This approach is similar to creating a map that shows how different parts of the network depend on each other. This makes it possible to group parameters that are closely related, making it easier to decide which parts of the network can be removed without significant loss of performance. [4]
The toolkit could be integrated directly into the project. Note that layers that should not be pruned, such as the output layer, must be specified manually.
Pv = pruning ratio, l. = local, g. = global
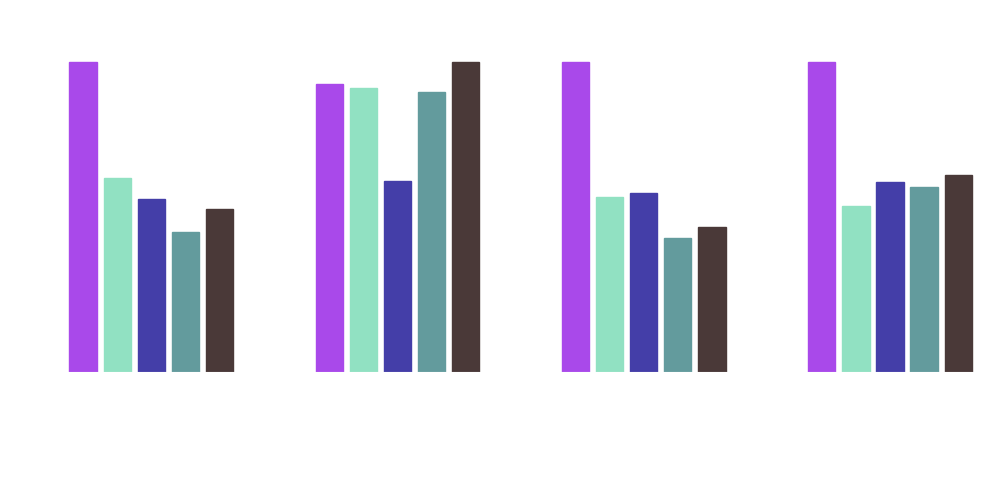
We applied different pruning methods to our neural network. We obtained the best results with magnitude pruning. Here we removed weights based on their size (magnitude), measured by the L1 and L2 norms. The L1 and L2 norms are common mathematical norms used in AI. We ran all pruning configurations both locally (within individual layers) and globally (across the entire network).
Our results were promising: with local pruning, we were able to remove up to 25% of the parameters with the L1 norm and up to 50% of the parameters with the L2 norm without significantly affecting performance. With global pruning, we were able to remove up to 20% of the weights with both norms before performance dropped significantly. We were able to see that pruning can actually lead to an improvement in performance, such as with global magnitude pruning with the L2 norm, suggesting that our model may be too complex and pruning allows for better generalization.
Overall, we were able to reduce the size of our model by up to 57% and improve the speed of inference by up to 46% without significantly affecting the accuracy of the model.
Quantization reduces the bit width of weights and activations in a model by converting decimal values to integer values. Quantization can reduce memory and computation time in a model by using lower precision data types, such as INT8 instead of FP32. This means that instead of 32 bits, only 8 bits are used to represent the weights in memory.
PyTorch provides several ways to perform quantization of a neural network. To perform quantization, quantization parameters must be calculated. This is done automatically by PyTorch and is used to scale the weights correctly. The quantization can be either static or dynamic. In static quantization, the quantization parameters needed to scale the values are pre-calculated using sample data, while in dynamic quantization, the parameters are calculated and adjusted during the pruning process. It is also important whether the parameters are calculated with or without retraining. This is referred to as Post-Training-Quantization (PTQ) or Quantization-Aware-Training (QAT).
In our project we decided to use static PTQ. PTQ is more resource efficient than QAT and PyTorch does not support dynamic quantization of the convolution layer. The goal is to quantize the parameters from FP32 to INT8. It is important to note that the quantization process must be specifically adapted to the future hardware on which the model will run.
By quantizing, we observed a more than 70% reduction in model size and a more than 50% improvement in inference speed. This improvement significantly increases the loss, but we have only a small reduction in the F1 score of 7%. An increase in the loss value indicates that our model has larger deviations from the actual values. Despite this increase, the small decrease in the F1 score shows that our model still provides satisfactory results in terms of accuracy.
Quantization turns out to be a powerful and easy-to-use tool to improve model size and inference speed. However, it can be made even smaller and faster. The two techniques, pruning and quantization, are not mutually exclusive, but can be combined to further reduce model size. We have quantized the already 25% pruned "Magnitude L2 global" model and tested the effects.
Finally, we would like to present all the tested configurations together. The graph shows very well the benefits that can be achieved by pruning and quantization.
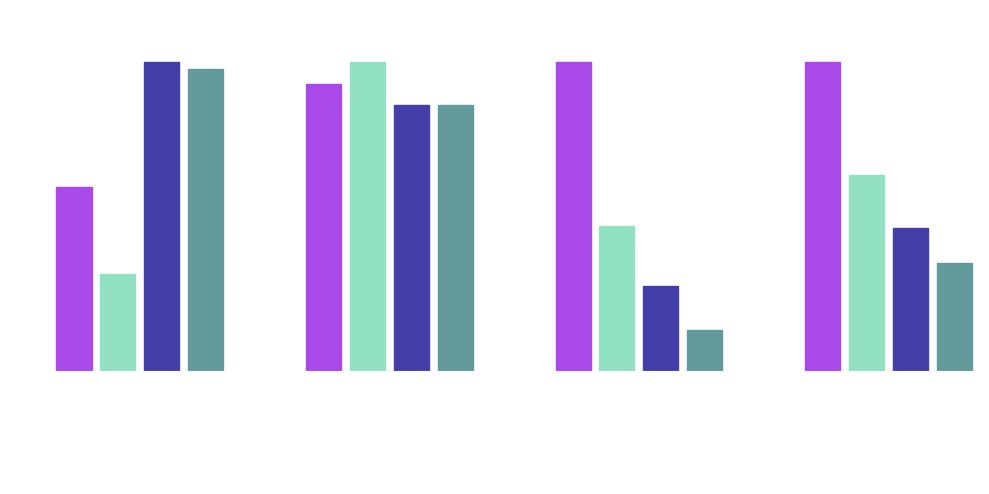
Compare results
The highest compression rate and the lowest inference speed were achieved with a combination of the two techniques, but the F1 score decreased the most and the BCE loss increased. Model size was reduced by up to 87% compared to the base model. Inference speed was improved by 65%. Given the improvements, a 7% reduction in F1 score is "acceptable" for this use case.
In this blog post, we introduced EdgeAI, its benefits and challenges and a potential use case. We also tested two techniques - pruning and quantization. These methods of model compression are a good starting point for overcoming the challenge of limited memory and processing power.
With pruning, in the case of magnitude-based L2 global pruning, we were able to reduce the model size by 57% and improve the inference speed by 46%, and the regularization effect is also evident. The technique made it clear that we can remove a certain number of parameters from our model without suffering large losses in model performance.
Quantization turns out to be an effective, easy-to-use technique for model compression. Using this method, we were able to achieve a 70% reduction in model size and a 50% improvement in inference speed.
The highest compression rate and the fastest inference speed were achieved with a combination of these two techniques. However, the performance of the model decreases the most. Compared to the base model, the model size is reduced by 87% and the model is 65% faster.
The benefits of these techniques are clear, and we believe they are an important step toward overcoming one of the challenges of EdgeAI. To further advance EdgeAI in the future, other issues, such as the power consumption of edge devices or privacy and security, could be addressed in more detail. In addition, the question of how to deploy and maintain the new AI models on the edge remains open and will be addressed in a future blog post. We want to combine the advantages of Kubernetes and Edge AI and give a possible outlook on MLOps at the edge.
Further information:
[1] https://www.fortunebusinessinsights.com/edge-ai-market-107023
[2] https://www.areinhardt.de/publications/2012/Reinhardt_SustainIt_2012.pdf
[3] https://www.mdpi.com/1996-1073/16/5/2388
[4] https://github.com/VainF/Torch-Pruning/tree/master
[5] https://www.sciencedirect.com/science/article/pii/S2667345223000196
