

Cybersecurity is more important than ever in today'sdigital world. With the current drastic increase of attacks on companies andorganisations, the need for good security practices is becoming even moreapparent. But in an environment increasingly supported by artificialintelligence (AI), we need to protect not only our systems and data, but alsothe AI models themselves.
The relevance of this topic is also demonstrated bythe fact that the security of AI-based applications is a component of Gartner's current top technology trends - AI TRiSM (AI Trust, Risk and Security Management). Thisframework includes solutions, techniques and processes for the interpretabilityand explainability of models (see blog article Explainable AI), privacy, model operation and defence againstattacks for customers and companies. Furthermore, 23 cybersecurity authorities from 18 countries have issueda guideline fordeveloping secure AI models.
In this blog article, we take a closer look at thesecurity of AI models and present a brief overview of the most common attackvectors. Find out how companies and organisations can protect themselvesagainst these threats and which security measures are essential to ensure theintegrity and functionality of AI models.
To differentiate the security of AI models fromgeneral IT security, it is important to understand that AI models often serveas the last line of defence, meaning they must detect and prevent unwanted ormalicious activity even when other security measures fail. While IT securityfocuses on securing networks, devices and applications, the security of AImodels specifically aims to ensure the integrity, robustness, and predictivequality of these models. Attacks on AI models can occur at different pointsduring their lifecycle (see blog article ML Lifecycle). In the following, we will look at differentscenarios and possible countermeasures.
If the attackers gain access to the training dataduring model development, they can worsen the performance of the model bymaking targeted adjustments to this data. This can be done, for example, byadding incorrect data, adapting existing data or changing the labels in thedata. In addition, the decision of the model can be influenced in favour of theattackers by adapting the training data using so-called triggers, i.e. themodel can contain a backdoor. In the case of images, these can be patterns, forexample, as shown in Fig. 1. The pattern is placed in training examples thatare all given the same label. In this way, the model associates thecorresponding class with the trigger and the decision of the deployed model canbe specifically influenced by the trigger.
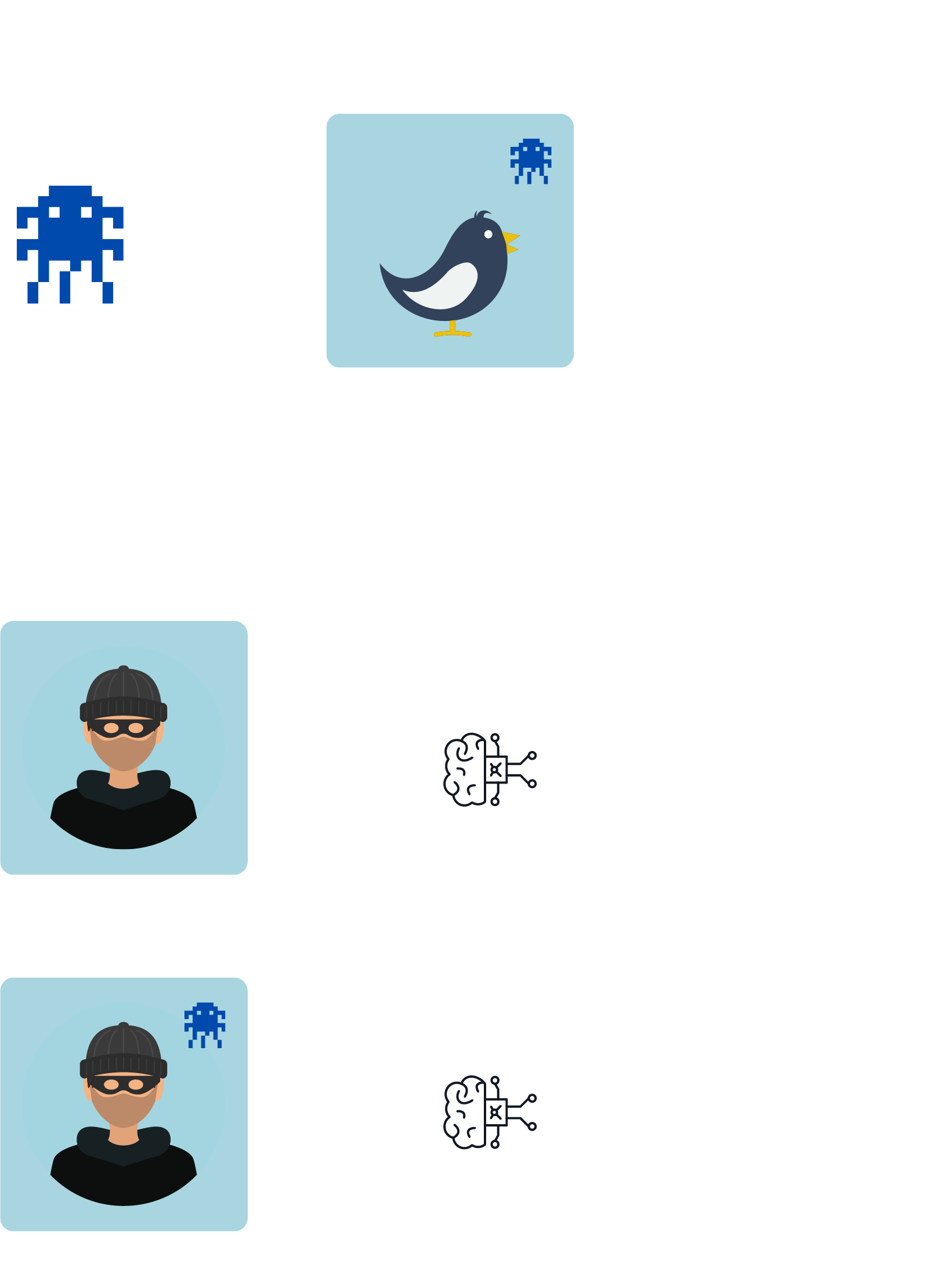
A successful attack is characterised by the fact thatthe model behaves normally for requests without the specific trigger, but forrequests that contain the trigger, it predicts the label desired by theattackers. This makes models with a backdoor difficult to identify if only theusual performance metrics are considered. In particular, if pre-trained modelsare used as the basis for your own development, potentially contained backdoorscan be transferred to your own model.
Pre-trained models should therefore only be used froma trustworthy source (supply chain security). Depending on the criticality ofthe use case, your own training data should be protected against unwantedmodifications by means of strict access restrictions, cryptographic procedures,and hashing.
So-called evasion attacks target models that havealready been deployed and operationalised. Attackers attempt to cause amisclassification of the model by modifying the input data in a way that isbarely perceptible to humans. As can be seen in Figure 2, in the case of imagerecognition models, the manipulation of just a few pixels is sometimes enoughto produce a drastically different model response.
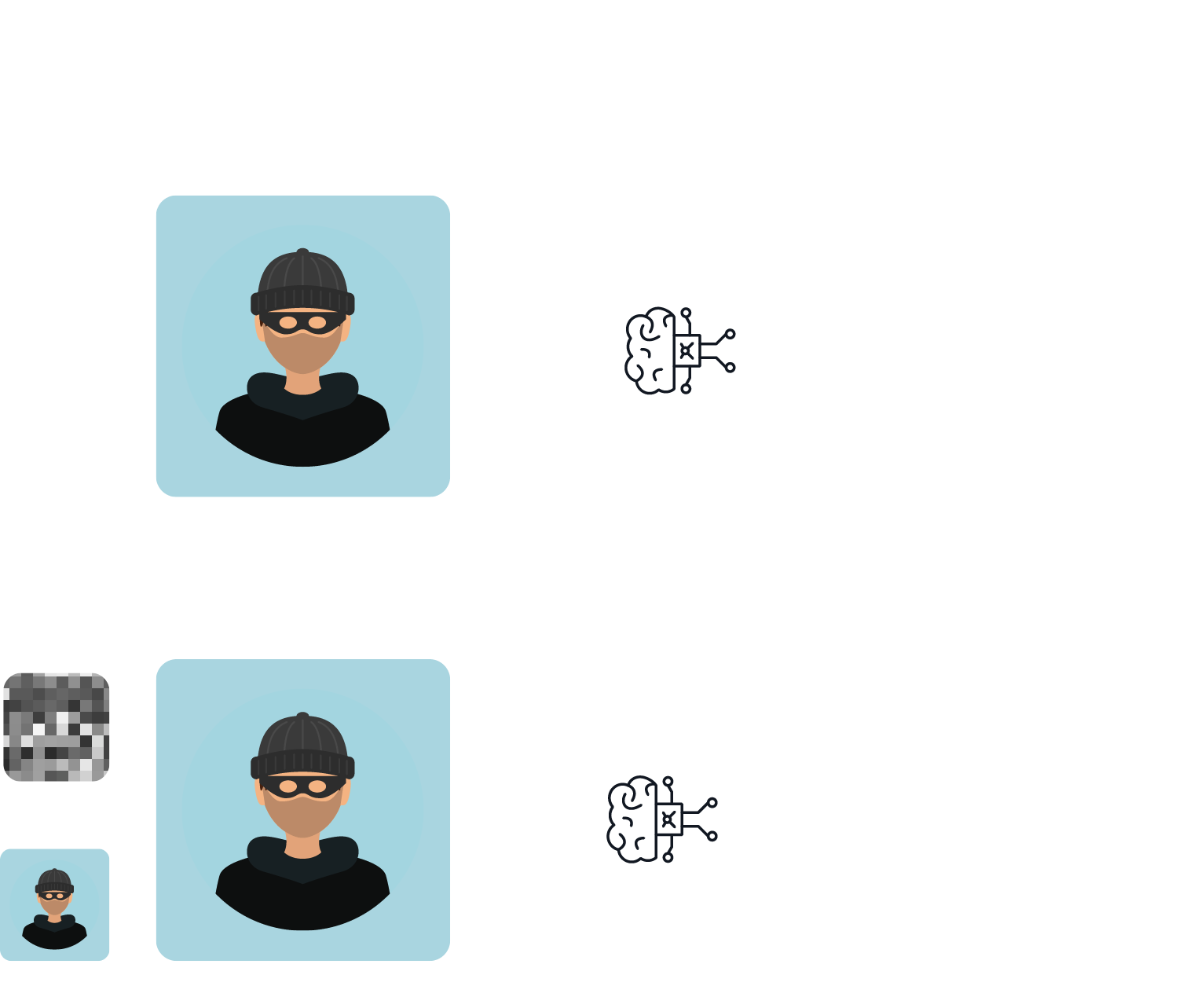
These attacks can be categorised into targetedattacks, where the attacker forces the model to predict the desired targetvalue, and untargeted attacks, which cause a general reduction in modelaccuracy or predictive confidence. Evasion attacks can take place in thephysical or digital world. In the past, for example, the targeted affixing ofindividual stickers to traffic signs has led to misclassifications byautonomous vehicles. On the other hand, the model request can also be digitallymodified, as in our example. This also applies to so-called large languagemodels, such as ChatGPT. These models are optimised through excessivefine-tuning to prevent the generation of toxic content, such as the creation ofpersonalised phishing emails. However, these safeguards could be circumventedby specifically adding text modules to the model request (https://llm-attacks.org/).
The same applies here - if a pre-trained model is usedas the basis for your own model development, its weak points can be transferredto your own model.
Identifying the slightly manipulated model queriesdiscussed above is difficult, as the changes are often very subtle. But modelscan be made more robust by anticipating such attacks, i.e. by includingslightly modified examples in the training data.
Information extraction attacks also target alreadydeployed and operationalised models to extract either the entire model or partsof the training data. The attackers can specifically search for confidentialinformation such as personal identification data, company secrets or othersensitive data. In worst-case scenario, a sufficient amount of data can beextracted from the model to enable a complete reconstruction of the model.
A common way to carry out these attacks is to use manycarefully crafted inputs to explore the model's functionality piece by piece.In addition, attackers can also try to find out whether a particular datasample has been used as part of a model's training data. This is problematicfor privacy reasons, as it can be used to reconstruct individual, potentiallysensitive data attributes, such as medical records or personal information.
This type of attack is facilitated when publiclyaccessible pre-trained models are used as the foundation for developing one'sown model, as many details about the model's functioning (e.g., itsarchitecture) are known in this case. Possible protective measures includeseverely restricting the model output, i.e. only making necessary informationfrom the model response accessible via an API. The data set for model trainingshould be cleaned of irrelevant sensitive information as far as possible. Inaddition, it should be ensured that the model generalises well and does notoverfit to the training data, i.e. learns it by heart.
In summary, there are several possible defencemechanisms for the various attack scenarios, which must be considered as fixedsteps in model development:
As a conclusion to our article, we would like toencourage you to take action and assess the safety of your own AI models,especially in view of the fact that such steps will be required in the nearfuture (see blog article AI Act).
https://www.ncsc.gov.uk/files/Guidelines-for-secure-AI-system-development.pdf
https://www.bsi.bund.de/SharedDocs/Downloads/EN/BSI/KI/Practical_Al-Security_Guide_2023.html
https://english.aivd.nl/publications/publications/2023/02/15/ai-systems-develop-them-securely
https://www.gartner.com/en/articles/what-it-takes-to-make-ai-safe-and-effective
